Deep Q-Materialization - Materialized View Management with Deep Reinforcement Learning
in Projects
Read the full paper on arXiv.
Materialized views have the potential to greatly boost query performance by reusing the results thus avoid expensive (re)computation.
Fundamentally, materialized views are just another form of derived data. Like managing any other derived data, we have to address three questions: 1. How to use the derived data, 2. What to maintain as derived data and 3. How to maintain them. In the context of managing materialized views, more specifically we need to answer 1. How to select views to materialize, 2. How to use the views to answer queries and 3. How to maintain materialized views to keep them up to date while satisfying constraints (if any).
Given a storage constraint, we could manage views with cache policies, e.g. LFU, LRU. Previous works also proposed state-of-the-art approaches based on the cost of views as well as estimated benefit of views. However, our study shows such heuristic-based approaches are insufficient because: 1. Their performance could change drastically on different workloads, 2. Their performance rely on accurate signals that might not be available in practical.
As our first step towards a view-oriented system, we propose to manage materialized views with Deep Reinforcement Learning. Our insight is that a better view selection policies can be effectively trained with an asynchronous RL algorithm which runs paired counterfactual experiments during system idle times to evaluate the incremental value of persisting certain views. Such an approach learns from doing and obviates the need for a hand-crafted heuristic.
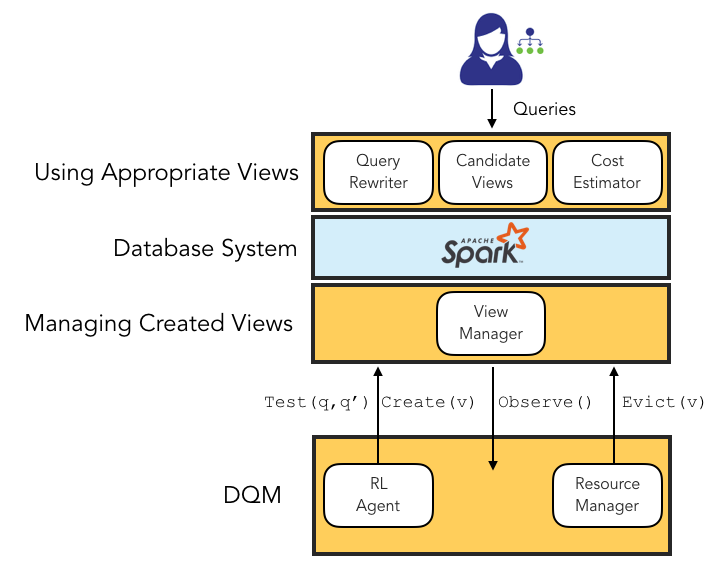
In this project, we formalize online view selection in opportunistic materialization systems as a Markov Decision Process. We propose a new async reinforcement learning algorithm for view selection and a new credit-based eviction model that can enforce storage constraint.
In our research prototype system called DQM, we focus on inner-join views. We implemented a view miner that can generate view candidates by mining the logical plan of queries, a query rewriter that can rewrite a query with a view and a view manager that can manage (create/drop) views. We integrate our system with SparkSQL and build our DeepRL agent for decision making (view selection and eviction) with Python that communicate with the Spark environment via the RESTful API.
We evaluate DQM with workloads derived from the Join-Order-Benchmark and TPC-DS. Results suggest that DQM is more robust on different workloads and perform competitively with a hypothetical near-optimal baseline. We also studied how different settings would affect DQM. For example, results suggest when we account maintenance cost, DQM is more effective due to its cost-aware selection and eviction policy.